|
Hello! I am currently a research engineer at Meta. Before that, I was a direct Ph.D. student (2020-2025) at Image and Visual Representation Lab, part of the School of Computer and Communication Sciences at EPFL, Switzerland. Under the guidance of Prof. Sabine Süsstrunk and Dr. Tong Zhang, I work on 3D Reconstruction and Perception, Image Diffusion, and Large Vision-Language Models (LVLMs). During my Ph.D., I did two internships, one NVIDIA Zurich on learning-based robot perception under Dr. Alexander Millane, another at Meta London under Dr. Filippos Kokkinos. Before my Ph.D. study, I earned my bachelor's degree from Zhejiang University, Hangzhou, where I was a member Advanced Class of Engineering Education (ACEE) in Chu KoChen Honors College, and was honored to receive the Chu Kochen Award. Email / Google Scholar / LinkedIn / GitHub |

|
|
🎉 [July 2025] I'm glad to share that I started a full-time role at Meta in the Multimodal Reasoning part! 🎉 [Feb 2025] Our paper on Text-guided Image Editing is accepted by CVPR 2025! Glad to see you in Nashville! 🎉 [Jan 2025] Our paper on low-overlapping Point Cloud Registration (PCR) is accepted by TMLR 2025! 🎉 [Aug 2024] I'm glad to share that I will work as an Research Scientist Intern on the GenAI LlaMA team at Meta London!
🎉 [March 2024] I'm glad to share that starting this March I will work as an Intern on 3D perception at NVIDIA in Zurich with the nvblox team! 🎉 [Oct, 2023]: The next International Conference on Computational Photography (ICCP) is happening at EPFL, Switzerland in 2024. I am excited to announce my role as website chair. 🎉 [Sept 2023]: I am invited for a talk at AWS LauzHack Cloud Research Day on DeepFakes detection. 🎉 [Aprl 2023]: I am admitted to the International Computer Vision Summer School (ICVSS). See you in Sicily 🏝! 🎉 [Aprl 2023]: My paper on generalizable implicit reconstruction VolRecon is accepted by CVPR! |
|
|
|
Yufan Ren, Konstantinos Tertikas, Shalini Maiti, Junlin Han, Tong Zhang, Sabine Süsstrunk, Filippos Kokkinos arXiv'25, Project Page, arXiv, Github, Dataset In this paper, we propose VGRP-Bench, a benchmark containing 20 visual grid reasoning puzzles with diverse difficulty levels that pose significant challenges for current Large Vision-Language Models (LVLMs). |
 
|
Yufan Ren, Zicong Jiang, Tong Zhang, Søren Forchhammer, Sabine Süsstrunk CVPR'25, Project Page, Code, arXiv, Video In this paper, we analyze these failure cases of Text-guided image editing and introduce a simple yet effective approach that enables selective optimization of specific frequency bands within spatially localized regions. |
|
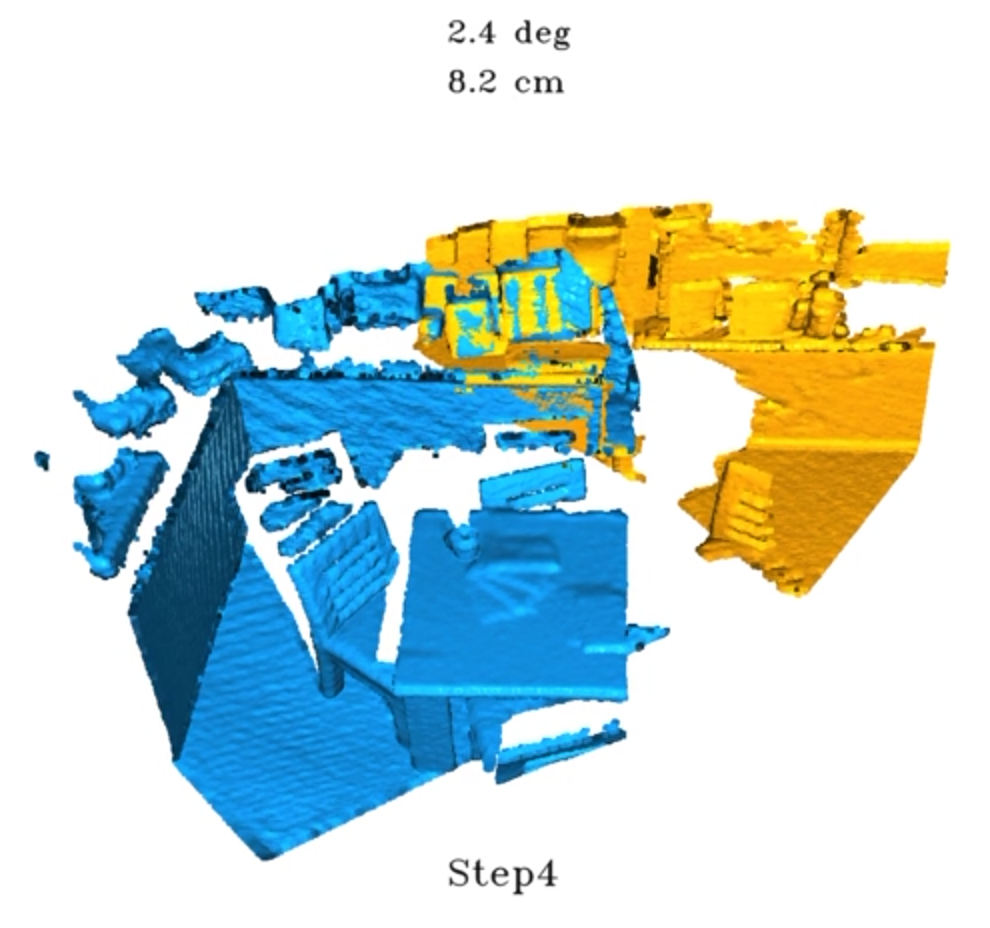
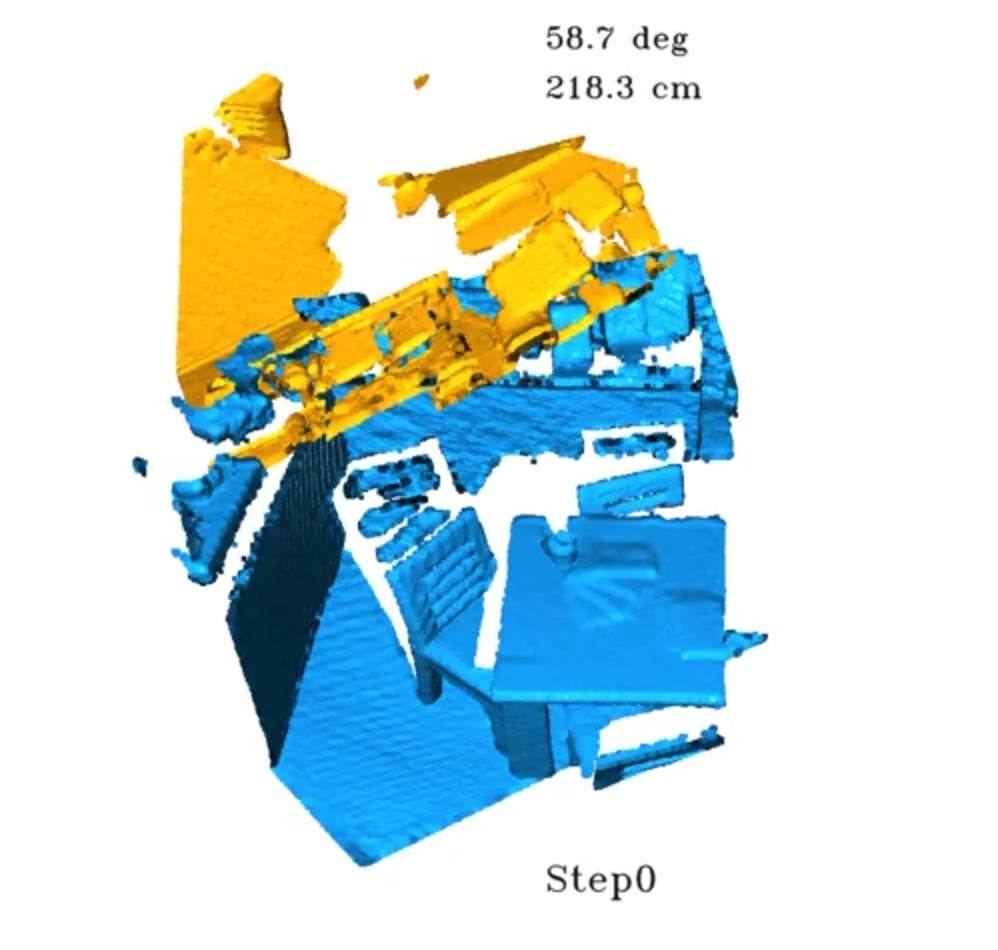
Zhi Chen*, Yufan Ren*, Tong Zhang, Zheng Dang, Wenbing Tao, Sabine Süsstrunk, Mathieu Salzmann TMLR'25, Project Page Point Cloud Registration (PCR) estimates the relative rigid transformation between two point clouds. We propose an adaptive multi-step refinement network that refines the registration quality at each step by leveraging the information from the preceding step, achieving state-of-the-art performance on both the 3DMatch/3DLoMatch and KITTI benchmarks. Notably, on 3DLoMatch, our method reaches 80.4% recall rate, with an absolute improvement of 1.2%. |
|
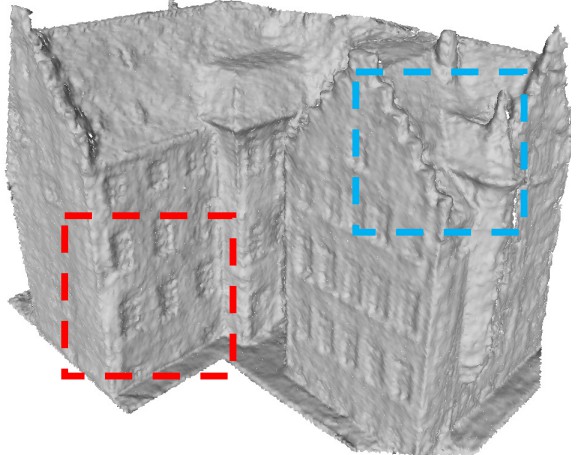
Yufan Ren*, Fangjinhua Wang*, Tong Zhang, Marc Pollefeys, Sabine Süsstrunk CVPR'23, arXiv, Project Page, Code We introduce VolRecon, a novel generalizable implicit reconstruction method with Signed Ray Distance Function (SRDF). To reconstruct the scene with fine details and little noise, VolRecon combines projection features aggregated from multi-view features, and volume features interpolated from a coarse global feature volume. |
|
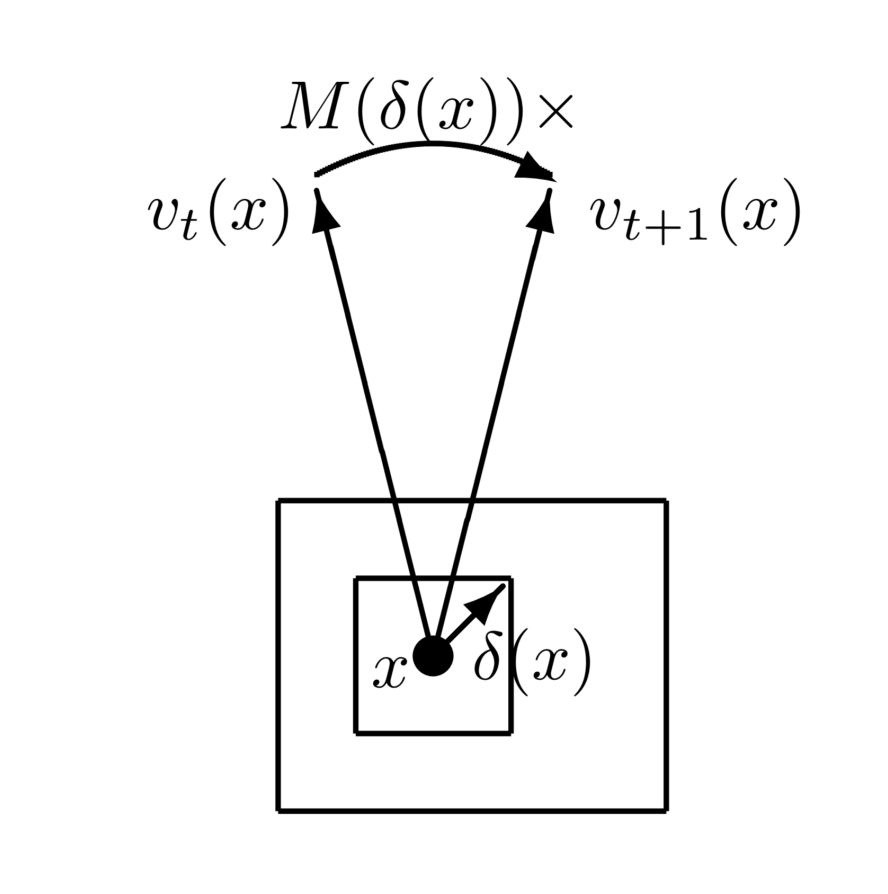
Ruiqi Gao, Jianwen Xie, Siyuan Huang, Yufan Ren, Song-Chun Zhu, Ying Nian Wu AAAI'22, arXiv We propose a representational model for image pairs such as consecutive video frames that are related by local pixel displacements, in the hope that the model may shed light on motion perception in primary visual cortex (V1). The model couples the following two components: (1) the vector representations of local contents of images and (2) the matrix representations of local pixel displacements caused by the relative motions between the agent and the objects in the 3D scene. |
 
|
Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, Long Quan CVPR'20, arXiv, Dataset We introduce BlendedMVS, a novel large-scale dataset, to provide sufficient training ground truth for learning-based MVS. To create the dataset, we apply a 3D reconstruction pipeline to recover high-quality textured meshes from images of well-selected scenes. Then, we render these mesh models to color images and depth maps. To introduce the ambient lighting information during training, the rendered color images are further blended with the input images to generate the training input. |
|
|
 |
Università di Catania, The school aims to provide a stimulating opportunity for young researchers and Ph.D. students. The participants will benefit from direct interaction and discussions with world leaders in Computer Vision. Participants will also have the possibility to present the results of their research, and to interact with their scientific peers, in a friendly and constructive environment. |
 
|
AI Singapore 2022, EPFL News Peter Grönquist and I did this challenge and won the 100,000 USD prize (incl. grant). In this challenge, we design machine learning models to detect three types of fakeness, i.e., fake faces (DeepFakes), manipulated audio, and mis-synchronization (lip-sync), and use engineering tricks to make it fast. |
Thanks for the awesome template of Jon Barron.